LSTM with K-Fold Cross Validation



Introduction
In the ever-evolving landscape of stock market predictions, one avenue that has gained considerable attention is sentiment analysis on social media, particularly X (formerly known as Twitter). I will continue this blog post from the previous one as promised albeit late. I'll walk through the intracacies of the final analysis that was conducted over last week, all the while navigating through the challenges posed by limited data and potential API costs.
The Model
To tackle the intricate dance between social media sentiment of the owner (Elon Musk) and stock prices, I employed a Long Short-Term Memory model. I am assuming that most people reading this article who are enthusiastic about stock prediction are aware of LSTMs. This architecture, with two of these layers and one last dense layer for the output, at the moment proves to be a promising result.
Data Exporation and Challenges
As any data scientist would attest, the journey behind with thorough data exploration. In my case, the main barrier was the X API cost and blocking of third party scrappers such as snscrape. This block restrained my approach to test on more data therefore I had to rely on other methods to improve the model.
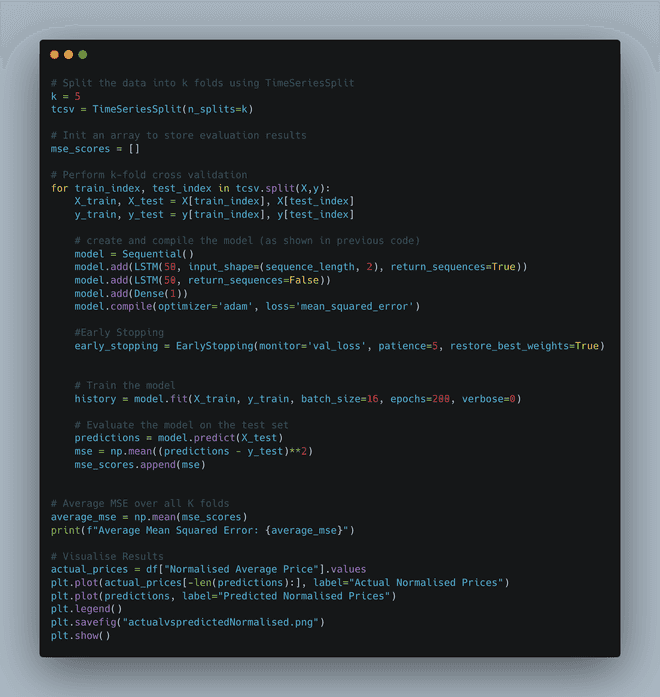
Handling Limited Data
To migitage the impact of limited tweets, I implemented a K-fold cross-validation, which allowed me to train the model effectively with the extracted data from one year back before the takeover of X (twitter). The time lag is evident from the final results below. The time lab observed in the predicted values compared to the actual values prompted me to tune the hyperparameters to reduce the time lag. I also did not want to overfit the model. Therefore, I am still trying to reduce this time lag but simultaneously balancing the overfitting.
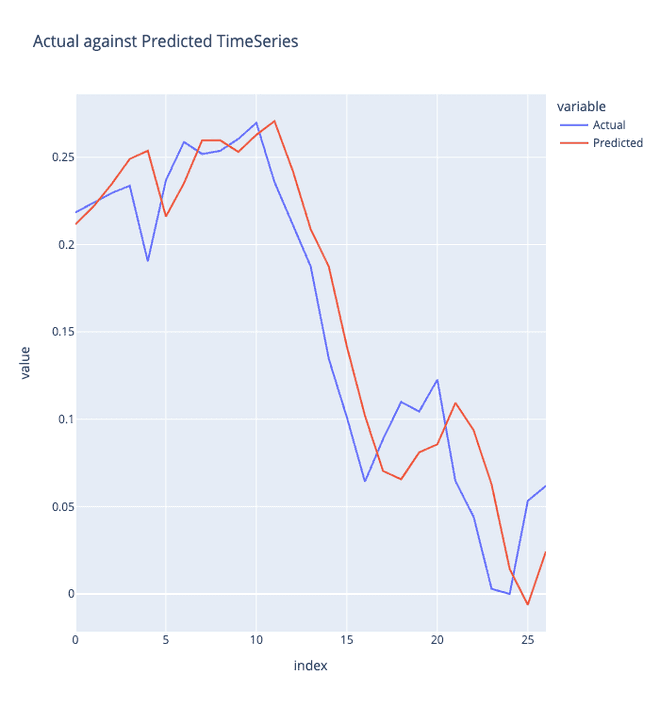
Looking Ahead
As the project stands, further work is needed to reduce the time lag and validate the model with new data. The "big if" factor comes into play here - if the results prove substantial, then the project can be deemed a success.
Conclusion
From data cleaning to tweet processing, and the application of sentiment analusis to normalising and scaling data, the journey has been one of constant exploration and adaptation. While challenges remain, the promise of uncovering patterns in sentiment that influence stock prices keeps the excitement alive.
In the realm of machine learning and stock prediction, each project is a step closer to ureaveling the complexities that govern financial markets. As I continue refining the model, the journey serves as a testament to the resilience required when navigating the ever-shifting landscape of data science and finance.
Thank you for reading this article. I will not be covering this project anymore. I will continue to take on the journey of application development in React Native, Android Studio and iOS development in the coming months as well as a little bit of Kubernetes.